

You may never have heard the term “crawl budget” before but it is one of the most important things you can know if you have a large website – especially websites that auto-generate pages based on search parameters. All search engines crawl websites, but in this blog we will focus on how Google determines your website’s crawl budget and why it’s important to optimize your crawl budget if you are seeking higher rankings in Google.
First, what is crawl budget?
Put simply, crawl budget is the amount of pages Google wants to crawl on your website within a given time. Google defines it as: “the number of URLs Googlebot can and wants to crawl”. A very simple example would be: your website has 300 total URLs and Google crawls the entire site once each month. This averages out to a crawl budget of roughly 10 pages per day.
There are many factors affecting crawl budget. These include:
- Crawl capacity – in short, how often Google can crawl your website without overloading your servers (crawl rate).
- In Google’s words: “Googlebot calculates a crawl capacity limit, which is the maximum number of simultaneous parallel connections that Googlebot can use to crawl a site, as well as the time delay between fetches. This is calculated to provide coverage of all your important content without overloading your servers.”
- Crawl demand – in determining crawl demand Google takes into account how many URLs you have, how popular the pages are and how stale the information is that Google has in their index. Put simply, if your content is updated frequently Google will want to crawl your site more frequently, thus your crawl budget will go up. This is why most SEO practitioners harp constantly about adding fresh, high quality content as often as possible.
Why you should care about crawl budget

Google crawls everything
Google crawls every URL they find on your website unless you tell them not to. This includes images, Javascript files, CSS files, PDF files, web pages etc. You may have tens of thousands of URLs on your website and only 1,000 real pages. How much time do you want Google to spend crawling URLs that are not important?
As an example: on one of my clients websites Google discovered 18,620 URLs. The website only has about 500 real pages. In very simple terms, if Google’s allotted crawl budget for the website is 100 URLs per day, it would take them 186 days to crawl all the discovered URLs. For this reason it is very important to provide Google with directives on exactly what pages are important and what pages to ignore.
New content may be getting indexed slowly

Whenever you add new, valuable pages to your website you want Google to find and index them as soon as possible. If Google is visiting useless pages on your website, it could take weeks (or even months) before they discover new content. In the meantime, if your competition has managed their crawl budget wisely, new key pages are being discovered ahead of yours – giving them an advantage in the rankings.
How to optimize your crawl budget
There are several ways to increase your site’s crawl budget, or at least end up with a more efficient crawl of your website.
Most important – setup your robots.txt file
The key to ensure your website is crawled efficiently is proper setup of your robots.txt file. A robots.txt file tells the search engine exactly what you want them to crawl and what they should ignore. Not all search engines respect the directives found in your robots.txt file but the good ones do (such as Google and Bing). This ensures that your most important pages are seen, and thus indexed, more quickly.
The robots.txt file contains one or more groups.
You should block pages that are unimportant by adding specific directives to the robots.txt file. These directives help search engines operate more efficiently by pointing them at the most important pages on your website without having to crawl every single URL.
Here is a basic example of a robots.txt file:

A side benefit of limiting what search engine crawlers can do on your website is conservation of server resources. If several robots are visiting your website each day and crawling an excessive number of pages it can slow the server response time.
Have an accurate sitemap
Google and other search engines use the websites xml sitemap as a guide. This file is usually located in the root directly of your website. If your sitemap is not accurate, Google (and some other search engines) will ignore it and go through the normal process of discovering all found URLs (unless they are guided by a well crafted robots.txt file).
For example: if your sitemap has links to 404 pages (page not found), Google will consider it unreliable and ignore it.
You can let Google know where your sitemap is through the robots.txt file, like this:
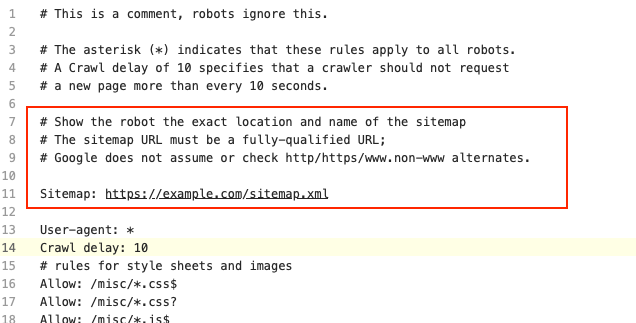
You can also give Google the exact location from within Google Search Console.
Add fresh content frequently
As mentioned previously, crawl demand is partially determined by the freshness of your content. If Google sees fresh, compelling content on a regular basis it will see a reason to visit your site more frequently and crawl more pages. Because googlebot crawls more frequently, your fresh content is indexed more quickly.
This doesn’t mean rehashing old blogs and saying the same old things in a different way. That could result in duplicate content issues, which can reduce your crawl budget. Writing content that is relevant, new and different is a major part of gaining Google’s respect and increasing your crawl budget.
This is why experienced SEO providers encourage website owners to commit to adding new content as frequently as possible.
Clean up crawl errors
There is a section in Google Search Console (GSC) called “Page Indexing”. You will find a subsection called “Why pages aren’t indexed”. Non-indexed pages are broken down into categories such as:
- Soft 404
- Not found (404)
- Blocked due to unauthorized request (401)
- Blocked by page removal tool
- Alternate page with proper canonical tag
- Blocked due to access forbidden (403)
- Page with redirect
- Duplicate without user-selected canonical
- Duplicate, Google chose different canonical than user
- Crawled – currently not indexed
- Duplicate, Google chose different canonical than user
- Discovered – currently not indexed
- Blocked by robots.txt
All non-indexed pages shown in Google Search Console have been crawled by Google. This list of non-indexed pages is a great place to start your journey toward crawl budget optimization. Take note of the pages Google is crawling but not indexing. In many cases Google knows these are useless pages (that is, they don’t index pages that will be no use to a visitor). Use that as a guide to setting up your robots.txt file.
It is also important to fix 404 errors and address duplicate content issues. All these will help you to improve your crawl budget and improve rankings.
Make sure you don’t have multiple home pages
It may sound funny, but some websites have 6 or more home pages. How is this possible?
If you type any of these into your address bar they will take you to Google’s home page:
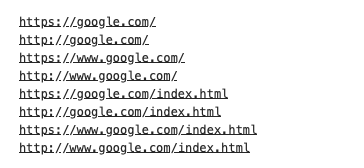
Notice that some of the URLs have the “http”, others “https”? Still others have “www” and some do not. Unless you redirect all of these to a single URL, Google may think you have multiple home pages. It may visit the www website and the non-www website. The www website is considered a subdomain of the non-www website. It can get confusing and messy, but the important thing is to have a single home page, not multiple.
I will cover more about this in another blog post but not having a single home page can result in Google crawling multiple websites. This would be very bad for your crawl budget and link authority.
The Takeaways
Site speed, responsiveness, internal linking, content quality and other on page SEO considerations are very important. But optimization of your crawl budget is just as important (if not more important in some cases).
In virtually every case where we have optimized crawl budget I have seen a lift in traffic. Apply the tips you have found in this blog and you will start to see an improvement as well.